Think of a transaction processing application as making a series of database updates. These updates can be made online or in a batch. An online update is a message that comes from a client. This is a general model that includes applications where users login to a host via terminal emulation sessions.
A batch update can be internally driven from the database, such as end-of-day processing, or externally driven such as when processing checks from a clearinghouse. The processing model in each case is a transaction or a unit of work initiated by client input such as a request to transfer funds from one account to another, or as the next logical unit of work such as posting interest on the next account.
To create a robust dual-site architecture, pay attention to the issue of database consistency. Below are several recommendations from FIS to implement a robust logical dual-site application with GT.M.
Package all database updates into transactions that are consistent at the level of the application logic using the GT.M TSTART and TCOMMIT commands. For information on commands, refer to the "Commands" chapter in the GT.M Programmer's Guide. For any updates not packaged, ensure that the database is logically consistent at the end of every M statement that updates the database; or that there is application logic to check, and restore application-level consistency when the database recovers after a crash.
Ensure that internally driven batch operations store enough information in the database to enable an interrupted batch operation to resume from the last committed transaction. In case of a primary system failure in the middle of a batch process, the secondary system can resume and complete the batch process.
If the application cannot or does not have the ability to restart batch processes from information in the database, copy a snapshot of the database to the secondary system just before the batch starts. In case of primary failure, restore the secondary to the beginning of the batch operations, and restart the batch operation from the beginning on the secondary.
Ensure that externally driven batch processing also has the ability to resume. The external file driving the batch operation must be available on the secondary before starting the batch operation on the primary. This is required to handle primary system failure during the batch process.
Additional requirements for application architecture are discussed in the "Messaging" section which follows. As previously noted, all processes accessing a replicated database must use the same Global Directory. Do not use M extended references since they can have unpredictable results.
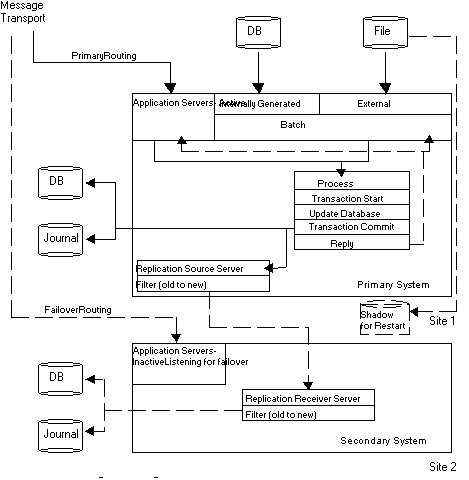
For online operations, application servers on the primary respond to messages from clients delivered over a network. Each message is assumed to result in zero (inquiry) or one (updated) transaction on the server. The network that delivers messages must be robust. This means that each message must either be delivered exactly once to an application server on the primary, or have a delivery failure with the client notified of the failure. It is recommended that the message delivery system be integrated with the logic that determines which system is primary and secondary at any time. The messaging system must be able to handle situations such as failure on the primary after the client transmits the message but before the primary receives it.
Application servers will typically respond to client messages with a reply generated immediately after the TCOMMIT for a transaction. It is necessary to make provisions in the application and message architecture to handle the scenario in which the primary fails after the TCOMMIT, but before the system generates a reply and transmits it to the client. In this case, the client would eventually time out and retry the message.
A logical dual-site application can handle this situation by designing the message structure to have a unique message identifier (MSGID), and the application to include the MSGID in the database as part of the TCOMMIT.
If the primary crashes after committing the transaction and the failover logic makes the former secondary the new primary, the retried message that has the same MSGID from the client will be received by the new primary. In this case, one of the following scenarios may occur:
The database shows that the transaction corresponding to the MSGID in the message has already been processed. The server could then reply that this transaction was processed. A more sophisticated approach would be to compute the response to the client within the transaction, and to store it in the database as part of the transaction commit. Upon receipt of a message that is a retry of a previously processed message, the server could return the previous response in the database to the client.
The database shows the transaction as unprocessed. In this case, the new primary will process the transaction. At this time, it is unknown whether or not the former primary processed the transaction before going down. If it was not processed, there is no issue. If it was processed, it would be rolled back when the former primary comes up as a secondary, and must be reconciled either manually or automatically, from the rollback report (since the result of processing the first time may be different from the result of processing the second time).
This section describes the system requirements that are necessary to implement an application with logical dual-site operation.
GT.M does not make any decisions regarding primary or secondary operation of an instance. A mechanism external to GT.M is needed to identify system status and to determine the primary and secondary systems. Use this mechanism during application startup.
To implement a robust, continuously available application, it is important that each application instance comes up in the correct state. In particular, there must be exactly one primary and either no secondary system or one secondary system. All database update operations on replicated databases must take place only on the primary, and there must be no logical database updates on the secondary.
![[Note]](images/note.jpg) | |
/mupip backup /online and mupip reorg /online update control information in the file header, not the database contents, and can operate freely on the secondary. |
Failover is the process of reconfiguring the application so that the secondary takes over as the new primary. This might be a planned activity, such as bringing down the primary system for hardware maintenance, or it may be unplanned such as maintaining application availability when the primary system or the network to the primary goes down.
Implementing and managing failover is outside the scope of GT.M. In designing failover, it is important to ensure that:
There is only one primary at any one time, and database updates only occur on the primary system. If there is no primary system, the application is not available.
Messages received from clients during a failover are either rejected, so the clients will timeout and retry, or are buffered and sent to the new primary.
If the former primary continues operation or is back online after a crash, it must operate as a secondary.
Failing to follow these rules may result in the loss of database consistency between primary and secondary systems.
A durable network link is required between the primary and secondary systems. The database replication servers must be able to use the network link via simple TCP/IP connections. The underlying transport may enhance message delivery, (i.e., provide guaranteed delivery, automatic failover and recovery, and message splitting and re-assembly capabilities); however, these features are transparent to the replication servers that simply depend on message delivery and message receipt.
A damaged or structurally inconsistent database file can and often will result when a system crashes. Before image journaling, normal MUPIP recovery/rollback will repair such damage automatically and restore the database to the logically consistent state as of the end of the last transaction committed to the database by the application. Certain benign errors may also occur (refer to the "Maintaining Database Integrity" chapter). These can be repaired on the secondary system at an appropriate time, and are not considered "damaged" for the purpose of this discussion.
| |
If the magnetic media of the database and/or the journal file is damaged (e.g., a head crash on a disk that is not mirrored), automatic repair is problematic. For this reason, it is strongly recommended that organizations use hardware mirroring for magnetic media. |
Considering the high level at which replication operates, the logical dual-site nature of GT.M database replication makes it virtually impossible for related database damage to occur on both primary and secondary systems.
There are two cases to consider in the unlikely event that there is database damage needing manual repair: damage on the primary and damage on the secondary. If the database needing repairs is operating as the primary, FIS recommends a failover so that the damaged database begins operating as the secondary. Then shut down replication, repair the database, and resume replication. The secondary system will automatically "catch up," assuming that the replication fields in the database file headers are correct.
To maintain application consistency, do not change the logical content of a replicated region when using DSE to repair a damaged database.
| |
Before attempting manual database repair, FIS strongly recommends backing up the entire database (all regions). |
After repairing the database, bring the secondary back up and backup the database with new journal files. MUPIP backup online will allow the secondary to come back online and resume operation while the backup takes place. The old journal files prior to the backup are not usable for recovery.
GT.M database replication ensures that the primary and secondary system databases are logically identical, excluding latency in replication to the secondary system. During rolling upgrades, the primary and secondary will be logically equivalent but the exact values of M global variables may differ.
All database updates to replicated regions must occur only on the primary system.
GT.M will replicate all changes to the database on the primary system to the database on the secondary system.
Logical dual-site operation with GT.M requires a procedure for a number of situations, including both normal operation and failure scenarios.
Although logical dual-site applications based on database replication can operate manually, the requirements are complex enough to warrant automation via scripting. It is essential to design, implement, and test the procedures carefully to provide an automatic failover to the secondary system within seconds. GT.M provides the required functionality to implement continuous availability via logical dual-site; however, a considerable amount of system engineering is required to implement it.
Basic application startup for each system is similar. The steps are modified for each scenario.
Determine current and prior system status (primary/secondary).
Perform necessary database recovery/rollback. Different failure modes have different recovery scenarios, which may include rollback of previously committed transactions for subsequent processing. Reconcile rolled back transactions automatically or manually.
Create new journal files. Although not required, this will simplify system administration.
Start the GT.M replication Source Server for this instance. For logical dual-site operation, you should bring up the Source Server on the secondary to establish the Journal Pool. In case of a failover, the new primary will need the Journal Pool to be established to replicate data to the new secondary. On the secondary, bring up the Source Server in passive mode. On the primary, bring up the Source Server in active mode.
Start the GT.M Receiver Server if this is the secondary instance.
If starting up as primary, start the application servers. The application servers can also be started on the secondary to facilitate a faster failover; however, it must be guaranteed that they do not perform updates of any replicated region on the secondary. GT.M replication does not explicitly check for this condition because when replication is being used as a real-time data feed from one application to another (as opposed to logical dual-site operation), concurrent updates to replicated regions on the secondary must be allowed.
If starting up as primary, and the state of the database indicates that batch operations were in process when the system went down, restart batch operations.
An initial startup of an application instance has no prior status. There are two ways to bring up a logical dual-site application: bring up the primary followed by the secondary, or bring both up at the same time.
When launching a dual-site application as a conventional single-site, versus launching it as a single-site for which a secondary will be launched later, the only difference is that the Journal Pool must be established before any M processes access the database. Bring up the Source Server in passive mode to create the Journal Pool. Then bring up the application. Later, switch the Source Server to active mode when the secondary comes up.
Perform database recovery/rollback to the last consistent state, since the system may previously have crashed. If the database was shut down cleanly, the recovery/rollback to the last consistent state is essentially a "no-op." This operation restores the database to the last committed transaction. There is no media damage.
Create new journal files.
Start the Source Server in passive mode.
Start the application servers.
If the state of the database indicates that batch operations were in process, restart batch operations.
An external agent must determine which is primary and which is secondary when bringing up both sites simultaneously.
Both databases must be logically identical and have the same journal sequence number. (When starting up, an instance considers its journal sequence number to be the maximum reg_seqno of any replicated region. Thus, if the primary and secondary do not have identical files, that is if they are logically identical but configured differently, ensure that at least one region on the secondary has reg_seqno and resync_seqno the same as the largest reg_seqno on the primary.) No rollback/recovery should be required on either site. If there is any possibility that the two are not identical, do not try to bring both up concurrently.
| |
FIS does not recommend starting both systems concurrently because of the possibility of a network or timing problem resulting in two primaries or two secondaries. |
FIS' recommended approach is to bring up the application as a single-site, and then bring up the secondary. Enable failover once the secondary catches up with the primary.
If restarting the secondary after a shut down, or after a crash that left the replicated regions untouched, simply starting it up will cause the primary to send transactions to it. It will automatically catch up once the Receiver Server is started. Do the following:
Recover/rollback database to last consistent state.
Create new journal files.
Start passive Source Server, and then the Receiver Server.
Start the passive application servers, if appropriate.
In this scenario, the database used to start up the secondary is logically identical to the database with which the primary started up, and has the same journal sequence number. When the secondary starts up, all transactions applied to the primary replicate to the secondary, while the secondary "catches up" with the primary. Do the following:
Load/restore the database.
Create new journal files.
Start passive Source Server, and then the Receiver Server.
Start the passive application servers, if appropriate.
Since the Source Server goes to the journal file to read transactions that are no longer in the journal pool, preserve all journal files on the primary along with the back pointers. This scenario is most applicable when it is not expected that the primary will be operational long before the secondary is up.
| |
All GT.M activity in the secondary instance must cease and any open database files must be run down before copying database files onto the secondary, or creating new database files and loading them with the extracts from the primary. |
The more common scenario for bringing up the secondary from the primary is to take a backup from the primary, transfer it to the secondary, and bring up the secondary. If the backup is a comprehensive backup, the file headers will store the journal sequence numbers.
The backup should use the /NEWJNLFILES switch of MUPIP backup to create new journal files. Once the secondary becomes operational, the Source Server will not need to go back prior to the backup to find transactions to send to the secondary.
Perform the following steps:
Load/restore the database. If the secondary database is not the comprehensive or database backup from the primary set, the journal sequence number from the primary at the instant of the backup must be set in the database file for at least one replicated region on the secondary.
Create new journal files without back pointers to previous generations of journal files with the /NOPREVJNLFILE flag. Since this database represents the beginning of this instance, it is not meaningful to have a previous generation journal file.
Start the passive Source Server and then the Receiver Server with the /UPDATERESYNC qualifier, along with the other startup qualifiers for the Receiver Server. Since the primary stores the last journal sequence number transmitted to the secondary, this qualifier is required to force replication to start from the actual journal sequence number in the secondary database. If it is not used, the Receiver Server may refuse to start replication since the journal sequence number in the secondary will be ahead of the journal sequence number at which the primary expects it to be.
Start the passive application servers, if appropriate.
Since the primary should not need to be rolled back to a state prior to the start of the backup, the generation link on the primary can be cut in the journal files created by the online backup command on the primary system. Use MUPIP SET /JNLFILE <JNL_FILE> /NOPREVJNLFILE to cut the generation link for the journal file <jnl_file><JNL_FILE>. Use the /BYPASS qualifier to override the standalone requirements of the set comma
Under normal operation, when going from dual-site to single-site the secondary shuts down. The Receiver Server and Update Process should be shut down, as well as any passive Source Server and any inactive application servers. The databases should be run down.
If you expect an extended shut down, the active Source Server on the primary can be switched to passive to prevent it from trying to connect with a secondary system. Under normal scenarios, the primary would simply be left untouched, so that when the secondary comes back up, replication resumes where it left off and synchronizes the secondary with the primary.
The following steps are appropriate when performing a controlled failover in which the primary and secondary switch roles. Such a step is necessary to bring the primary down for maintenance. In the following steps, A is the former primary and new secondary, while B is the former secondary and new primary.
If you have a choice, choose a time when database update rates are low to minimize the clients that may time out and retry their messages, and when no batch processes are running.
The external system responsible for primary/secondary status identification should be told that Site B should now be the primary system and Site A should now be the secondary. If the messaging layer between clients and servers differs from the external control mechanism, command it to route messages to the secondary. There may be a need to hold messages briefly during the failover.
On A:
Stop the application servers.
Shut down the replication Source Server with an appropriate timeout. The timeout should be long enough to replicate pending transactions to the secondary, but not too long to cause clients to conclude that the application is not available. The GT.M default is 30 seconds.
Perform the rollback for the primary restarting as secondary.
Wait for B to become functional as the primary, and then query B as to the journal sequence when it became primary, and roll back to this number. Transactions that are rolled off the primary become "non-replicated transactions" that must subsequently be reconciled on B, either automatically or manually.
Create new journal files.
Start the passive Source Server, and then the Receiver Server.
Start the passive application servers, if appropriate.
On B:
Shut down the Receiver Server with an appropriate timeout.
Create new journal files.
Make the passive Source Server active.
Start the application servers (if they were previously passive, make them active).
If the state of the database indicates that batch operations were in process, restart batch operations.
Begin accepting online transactions.
If the network from clients to the primary fails, and the network from the clients to the secondary is still functioning, this warrants a failover from the primary to the secondary.
If the network from clients to both the primary and secondary fails, the application is no longer available.
If the network between primary and secondary fails, no action is required to manage GT.M replication. The primary will continue to make the application available. The secondary will catch up with the primary when the network is restored.
If the network from the clients to the secondary fails, no action is required to manage GT.M replication, although it would be prudent to make the network operational as soon as possible.
When the secondary comes back up after failure, it will still be the secondary. Refer to the preceding "Secondary Starts After a Shut Down or Crash" description for further details.
If the primary (A) fails, the secondary should take over; when the primary comes back up, it should come up as the new secondary.
The external control mechanism should detect that the primary has failed, and take action to switch the secondary to primary mode, and either route transactions to the new primary (former secondary) or notify clients to route transactions to the new primary.
If the former primary did not respond to certain transactions, one cannot be certain whether they were processed and whether or not the database updates were committed to the former secondary. These transactions must now be processed on the new secondary. When the former primary comes up as the new secondary, processed transactions and database updates will be rolled off the primary and must be reconciled.
On B:
Stop the Replication Server.
Create new journal files.
Switch the Source Server from passive to active mode to start replicating to the new secondary (former primary) when it comes back up.
Start the application servers, or if they were passive, they should be activated. The new primary is now ready to receive transactions from clients.
If the state of the database indicates that batch operations were in process, restart batch operations.
When Site A comes back up, query Site B as to the journal sequence number at which it became primary, and roll back the secondary database on A to this point. Transmit the transactions that were backed out of the database by the rollback to the primary for reconciliation/reapplication.
Create new journal files.
Start the Source Server in passive mode.
Start the Receiver Server to resume replication as the new secondary. Dual-site operation is now restored.
As appropriate, start the passive application servers.
Various dual-site failure scenarios are possible. Each case is characterized by a full system outage - i.e., the application is no longer available. This section identifies the recovery mechanism for each scenario. In each scenario, Site A is initially the primary and Site B is initially the secondary, before any failure.
In the following scenarios, the secondary site fails first. Once the secondary system fails, the primary continues to operate. The primary system's replication Source Server is unable to send updates to the secondary system. Thus, there is a queue of non-replicated transactions at the failure point on the primary. Then, the primary site fails before the secondary site recovers, which leads to a dual-site outage. Operating procedures differ according to which site recovers first.
Site A Recovers First
On Site A:
Rollback the database to the last committed transaction (last application-consistent state).
Create new journal files.
Start the Source Server.
Start the application servers. Application availability is now restored.
If the state of the database indicates that batch operations were in process, restart batch operations.
On Site B, when it recovers:
Rollback the database to the last committed transaction.
Create new journal files.
Start the Source Server in passive mode.
Start the Receiver Server. Dual-site operation is now restored.
Start the passive application servers, as appropriate.
Site B Recovers First
On Site B:
Rollback the database to the last committed transaction (last application-consistent state).
Create new journal files.
Start the Source Server.
Start the application servers. Application availability is now restored.
If the state of the database indicates that batch operations were in process, restart batch operations.
On Site A, when it recovers:
Query the primary as to the journal sequence number at which it became primary, and roll back the secondary database to this point. Transmit the transactions that were backed out of the database by the rollback to the primary for reconciliation/reapplication.
Create new journal files.
Start the Source Server in passive mode.
Start the Receiver Server to resume replication as the new secondary. Dual-site operation is now restored.
Start the passive application servers, as appropriate.
In the following scenarios, the primary site fails first, causing a failover to Site B. Site B operates as the primary and then fails.
Site B Recovers First
On Site B:
Roll back the database to the last committed transaction (last application-consistent state).
Create new journal files.
Start the Source Server.
Start the application servers. Application availability is now restored. If the state of the database indicates that batch operations were in process, restart batch operations.
On Site A, when it recovers:
Query the primary as to the journal sequence number at which it became primary, and the secondary database should be rolled back to this point. Transmit the transactions backed out of the database by the rollback to the primary for reconciliation/reapplication.
Create new journal files.
Start the Source Server in passive mode.
Start the Receiver Server to resume replication as the new secondary. Dual-site operation is now restored.
Start the passive application servers, as appropriate.
Site A Recovers First
On Site A:
Roll back the database to the last committed transaction (last application-consistent state).
Create new journal files.
Start the Source Server.
Start the application servers. Application availability is now restored.
If the state of the database indicates that batch operations were in process, restart batch operations.
On Site B, when it recovers:
Roll back all transactions that were processed when it was the primary. Transmit the transactions backed out of the database by the rollback to the primary for reconciliation/reapplication.
Create new journal files.
Start the Source Server in passive mode.
Start the Receiver Server to resume replication as the new secondary. Dual-site operation is now restored.
Start the passive application servers, as appropriate.
A complex dual-site failure may result in a large number of non-replicated transactions, depending on how the systems restart. This situation occurs if both systems are down, the secondary comes up for a period, assumes primary status, and then fails again while the original primary remains down.
If the original primary comes up first after the second failure, represented as Site A in Figure 7.3, it will be primary. When Site B comes up, it will act as the secondary and be forced to rollback all transactions performed while it was primary and Site A was down. These transactions become non-replicated transactions. If Site B came up first, then the non-replicated transactions would occur when Site A restarted. These would be the transactions while A was primary after B failed.
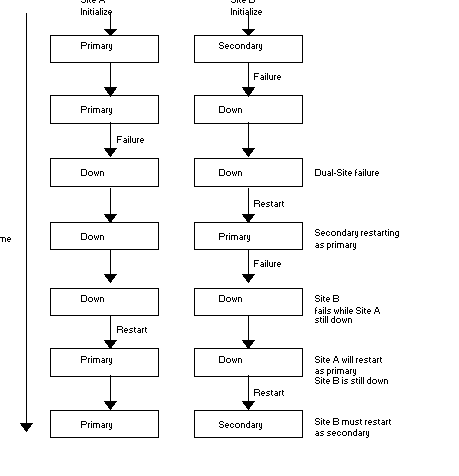
When recovering from these situations, the primary is always the current system of record when the secondary comes up. The secondary must roll its database back to the transaction with the highest journal sequence number for which both systems are known to be in agreement, and "catch up" from there. All transactions backed out of the database as part of the rollback must then be reconciled on the primary.
A rolling software upgrade provides continuous service while a new software release gets applied to the system. In short, each system is updated with the new software release independently, while the other system acts as primary during that period, removing the need for application downtime during the software upgrade.
This rolling upgrade sequence assumes that there is only a secondary instance, which is down during the upgrade. Thus, if the primary goes down during the upgrade, the application will be unavailable. Assuming that Site A is the primary before the upgrade, here are the steps to perform a rolling upgrade:
Site A continues to operate normally, (i.e., to the primary a secondary upgrade looks like a secondary failure).
On Site B:
Shut down the Source and Receiver Servers and the application. Run down the database and make a backup copy.
Upgrade the software.
If there is no change to the database layout or schema, bring the secondary back up and proceed with the planned failover (below).
Note the largest journal sequence number in any replicated database region.
Upgrade the database.
Set the journal sequence number of any replicated region to the largest journal sequence number noted above.
If there was no change to the database schema, bring the secondary back up and proceed with the planned failover (below).
If there was a change to the database schema, bring up the secondary with the new-to-old filter on the Source Server, and the old-to-new filter on the Receiver Server.
At this point, dual-site operation is restored with Site B running the new software and Site A running the old software. It may be appropriate to operate in this mode for some time to verify correct operation.
Failover to Site B as the primary and Site A as the secondary. Verify that the new software is operating correctly.
On Site A:
Once you are satisfied with the operation of the new software on Site B, shut down the Source and Receiver Servers and the application. Run down the database and take a backup copy.
Upgrade the software.
If there is no change to the database layout or schema, bring the secondary back up. Dual-site operation is now restored, and the upgrade is complete.
Note the largest journal sequence number in any replicated database region.
Upgrade the database.
Set the journal sequence number of any replicated region to the largest journal sequence number noted above.
If there was no change to the database schema, bring the secondary back up. Dual-site operation is now restored, and the upgrade is complete.
If there was a change to the database schema, turn off the filters on Site B. Then bring up the secondary on Site A. Dual-site operation is now restored. This filter can be turned off on Site B, or by the Receiver Server on Site A when it comes up, using the /STOPSOURCEFILTER command.
While a typical upgrade may take hours, significant upgrades may take even longer. During a site upgrade, only the one primary system is available. If this is an unacceptable risk to application availability, a tertiary instance can be used so that a primary and a secondary are always available. Please consult FIS to further discuss this procedure.
Filters between the primary and secondary systems are required to perform rolling upgrades that involve database schema changes. The filters manipulate the data under the different schemas when the software revision levels on the systems differ.
GT.M provides the ability to invoke a filter; however, the application developer must write the filters specifically as part of each application release upgrade when schema changes are involved.
Filters should reside on the upgraded system and they should use logical database updates to update the schema before applying the updates to the database. The filters should be capable of invoking the replication Source Server (new schema to old) or the database replication Receiver Server (old schema to new), depending on the system's status as either primary or secondary.