GT.M database replication provides the ability to implement continuous application availability, using a primary and secondary system, in case of complete system failure in one or more of the following components:
Either the primary or secondary system
The network between systems
The network between clients and the primary system
The MUPIP utility program can enable or disable replication independently for each database region. Refer to the "MUPIP" chapter for more information. When replication is turned on for a database region, all updates to that region on a primary system replicate in near real-time on the database of a secondary system.
The following steps characterize database updates. The first two steps occur with or without replication:
The journal file is written.
The database is updated.
The logical (M-level) journal file entry is delivered to a replication Source Server which in turn delivers it to the secondary system.
Once the first step completes, the transaction is recoverable even if the primary system crashes.
GT.M replicates the database by transporting the control records and M-level update journal records generated at the primary system to the secondary system and applying them there.
Since the secondary system may be very distant from the primary system, the GT.M database replication design allows the primary system to commit transactions before it receives acknowledgement from the secondary system. Therefore, transaction commits at the primary system and data transfers to the secondary system occur asynchronously. This process affects the design of applications used to export the benefits of logical dual-site operation. The process requirements are discussed later in this chapter.
If the secondary system or the communication link fails, it can lag behind the primary system until the two systems reestablish communication. Then, GT.M will automatically cause the secondary system to then catch up from the point of failure.
The M database is replicated via M-level journal records. The journal records are replicated as units related to a database transaction, i.e., within a transaction fence (TStart, TCommit, ZTStart, ZTCommit). Replication to the secondary system is asynchronous with the transaction on the primary system. This means that the primary system transaction will complete, creating appropriate journal records independent of the replication (movement) of the database updates to the secondary system.
Of the three events that occur as a function of a database update transaction, completion of the first step ensures that the transaction is recoverable. The completion of the transaction is independent of the delivery of the journal records either to the primary system's replication Source Server or to the secondary system.
For optimum recovery, the replicated updates are moved to the secondary system at a rate as close to their creation rate as possible, since they must be protected from loss to the secondary system in case of loss of the primary. For optimum performance on the primary system, disk I/O related to the replication process should be zero (i.e., the replication Source Server process should be able to operate without reading from or writing to disk). To achieve this, the network connection and the software subsystem of the secondary must have adequate bandwidth for peak update rates on the primary.
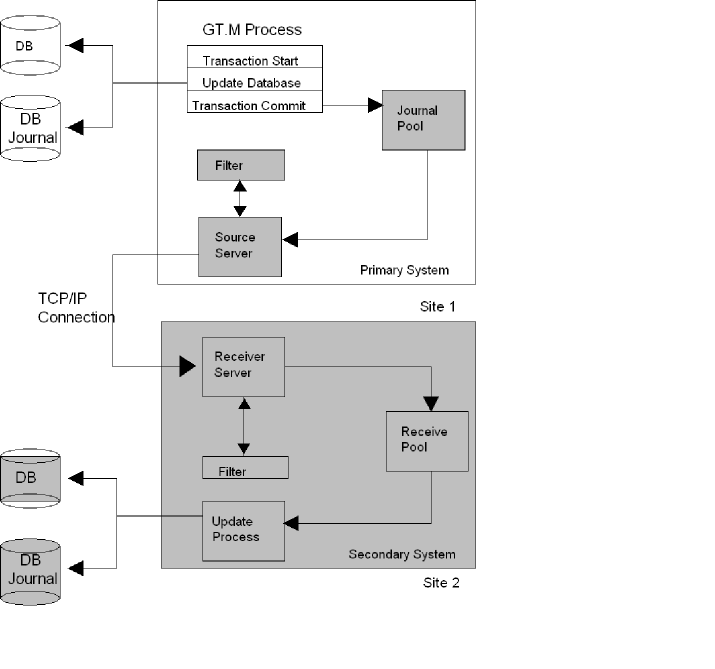
Figure 7.1. GT.M Recovery Architecture
![[Note]](images/note.jpg) | |
All GT.M processes accessing a replicated database must use the same Global Directory. M-extended references are not allowed. |
Database replication is a general-purpose tool. Although the primary emphasis in this manual is logical dual-site operation, GT.M database replication can also be used to do the following:
Provide a real-time data feed from a database to another system where a different application runs. Restrictions on updating replicated regions on the secondary system do not apply if the secondary is not used as a backup for the primary.
Implement a logical, triple-site operation to provide for continuous application availability in scenarios where two sites can fail.
Database replication requires before-image journaling to be enabled and turned ON. If it is OFF, GT.M turns it on when replication is turned on.
A GT.M process writes journal records to a journal buffer and then flushes them to a disk. The process writes the updated journal records to a shared memory segment called the Journal Pool that is shared by all processes using the same Global Directory.
The Source Server process transports each record from the Journal Pool to the secondary system via a TCP/IP connection.
The Journal Pool contains copies of journal records that the Source Server must send to the secondary system. To avoid disk I/O in normal operation, this shared repository buffers, in memory, the journal records not yet sent to the communication channel.
The order that transactions insert journal records into the pool determines a global transaction sequence known as a "journal sequence." GT.M does not interleave journal records for different transactions in the Journal Pool; therefore, the journal sequence uniquely determines a global transaction sequence. This global order is recorded in the JNL_SEQNO field of the journal update records. Every GT.M transaction, that updates at least one replicated region, increments the JNL_SEQNO by one.
For performance reasons, GT.M processes write records into the Journal Pool as if it were a circular buffer without concern for buffer overflow. If the Journal Pool overflows, the Source Server detects the condition and automatically obtains the journal records from the journal files and sends them to the secondary system in journal sequence order.
| |
Resynchronization is implemented with the same mechanism. At reconnection time, transactions needed for resynchronization are read from the journal files and sent to the secondary in journal sequence order. |
The Journal Sequence Number is recorded in the JNL_SEQNO field in the update journal records (specifically of type JRT_SET, JRT_KILL, JRT_FSET, JRT_FKILL, JRT_GSET, JRT_GKILL, JRT_TCOM). This value is set in the journal records, and written into the journal buffer and Journal Pool. The JNL_SEQNO is also copied to the reg_seqno field of the file header of each replicated region updated in the transaction.
All journal update records for a single transaction have the same JNL_SEQNO. Journal update records that belong to different transactions have different JNL_SEQNOs. The JNL_SEQNO reflects the strict sequential order applied to transactions in the database. (Without replication, the normal ordering of transactions is a topological sort order. Replication imposes a strict numeric sort order.) This approach provides a consistent, global transaction order across all replicated regions. The JNL_SEQNO helps synchronize the systems when the systems are not synchronized (i.e., when the secondary system is catching up after a communication failure).
| |
Forced removal of the Journal Pool terminates GT.M processes that are attempting to access the journal. Do not delete the Journal Pool unless explicitly instructed by Fidelity |
Before any database activity, the Source Server must be started in either active or passive mode so it can transfer journal records from the Journal Pool to the communication channel. The Source Server sets up the shared structures of all replicated regions and creates the Journal Pool. Before replication can occur, every replicated database region must be rundown and the Source Server must be started.
When starting up in active mode, the Source Server computes the startup value of JNL_SEQNO from the REG_SEQNO in the file headers. The startup value is the last saved consistent state (the maximum REG_SEQNO in any file header).
In passive mode, the Source Server acts as a stand-by server, waiting to activate in case of a failover. When a passive server is started, it computes the startup JNL_SEQNO. When a passive server is activated, it establishes a connection with the specified Receiver Server, and operates as a Source Server in active mode.
The sequence number from which the Source Server starts transmitting updates to the secondary is jointly determined by the Source Server and Receiver Server.
The Source Server automatically locates the journal update records from either the Journal Pool or the journal file, and sends them to the Receiver Server on the secondary.
GT.M provides the functionality for an application to provide continuous availability even as the application is periodically upgraded. This capability is called rolling upgrades. Since an application upgrade may involve a database schema change, GT.M provides for a filter to be inserted into the replication stream. This filter will either upgrade the schema if the secondary is running the newer version of the application software, or downgrade it if the primary is running the newer version.
If you specify a filter, the Source Server will send the replication stream to the filter, and the output of the filter, to the Receiver Server on the secondary system. Refer to the "Filters" section for more information.
The Source Server automatically handles buffer overflows in the Journal Pool and failure in the communication channel. When the next update to be transmitted is not in the Journal Pool, the Source Server automatically retrieves the record and subsequent records from the journal files until it catches up. The Journal Pool can overflow when the secondary is down. Once it catches up, the Source Server sends records from the Journal Pool. When journal files are switched, the new journal files have a back pointer to the old journal files so that the Source Server can find needed update records.
Since the Source Server searches through old journal files when bringing a secondary back in synchronization, it is not safe to delete or move old files until the transactions are permanently on the secondary system (i.e., the transactions in the journal files should be on the secondary database and backed up). Also, assure that the Source Server will never attempt to access them again. Refer to the "Switching Journal Files" section for the MUPIP commands to perform journal file link changes.
If the connection is broken (e.g., due to secondary system failure) the Source Server periodically tries to reestablish a connection with the Receiver Server. Once it establishes this connection, the Source Server waits for a restart message from the other end and sends journal records from the point requested by the Receiver Server. The restart message sent by the Receiver Server contains the restart point and information that instructs the Source Server to either deactivate any currently active filter or maintain the existing filter, if any.
Flow control is implemented between the Source and the Receiver Servers. When the Source Server receives a message to stop sending journal records, it stops until it receives a restart request. When the Source Server restarts, it reads from the Journal Pool and from the journal files, if necessary.
| |
GT.M provides an interface for deactivating an active Source Server (i.e., changing an active mode server to passive mode). Refer to "Starting the Source Server" section for more information. |
A keep-alive protocol ("heartbeat") between the Source Server and Receiver Server detects problems with the communication channel. Specifically, the Source Server periodically sends a heartbeat message to the Receiver Server. For every message sent, the Source Server expects a heartbeat response from the Receiver Server within a specified period. If a heartbeat response does not arrive within that period, the Source Server starts a recovery process in a manner similar to that triggered by a communications failure.
The Source Server logs its actions and errors in a log file. It also periodically logs statistics such as the current backlog, the number of journal records sent since the last log, the rate of transmission, the starting and current JNL_SEQNO, and the path of the filter program, if any.
It is possible to determine whether the Source Server is running by using a GT.M interface that reports the system status. Refer to "Starting the Source Server" for more information. The server can be restarted if it is no longer running due to forced termination. In this instance, the Source Server establishes a connection with a specified Receiver Server without performing initial steps of region startup, Journal Pool creation, and computation of the startup JNL_SEQNO.
| |
The Source Server must have previously created the Journal Pool in order to restart. |
The Receiver Server receives the journal records sent by the Source Server from the primary and puts them in the Receive Pool for future processing. This shared buffer is analogous to the Source Server's Journal Pool. An Update Process then updates the database from the Receive Pool.
The Receiver and Source Servers treat initial and post-recovery startup in a similar manner. Upon startup, the Receiver Server creates the Receive Pool, starts the Update Process, and waits until the Update Process informs it of the reference point for starting (or restarting) the transmission of journal records from the primary. Then, the Receiver Server waits for a connection request from the primary. Once it receives the request, the Receiver Server sends a request to the Source Server to start or restart transmitting journal records from the specified reference point. The Receiver Server tags the restart message with a flag. A startup option controls the value of this flag. Based on the startup option, the flag value is set to indicate whether the Source Server should stop any active filter or maintain the existing status of the filter.
| |
It is not possible to add or insert a filter if you did not specify one upon starting the Receiver Server. |
The Receiver Server waits to receive journal records. If the connection breaks during this time, the Receiver Server waits for a connection request from the primary system. The Receiver Server puts the records in the Receive Pool in the order they are received. The TCP/IP connection maintains the order of the journal records in transmission.
If any application filter is active, the Receiver Server collects the received journal records into groups of records that belong to the same transaction, and inputs each group into the filter. Then, the Receiver Server puts the filter output into the Receive Pool.
The Receiver Server treats the Receive Pool like a circular buffer. When the Receiver Server notices that the space occupied by unprocessed input in the Receive Pool is about to exceed a threshold, it sends a message to the Source Server to stop sending journal records. When the Receiver Server detects that the Receive Pool has adequate free space, it sends the Source Server a message to restart the process of sending journal records from the point that the process stopped.
The Receiver Server logs its actions, errors, statistics, starting and current JNL_SEQNO, and the path of the filter program, if any, in a log file. The Receiver Server participates in the keep-alive protocol by responding to every heartbeat message it receives from the Source Server with another heartbeat message. The heartbeat message from the Receiver Server contains the last JNL_SEQNO the Update Process successfully processed. The Receiver Server also periodically checks to see if the Update Process is running. If the Update Process is not running, the Receiver Server logs an error message. It continues logging error messages until an Update Process starts. The Receiver Server will not automatically start an Update Process.
GT.M provides an interface for determining whether the Receiver Server is running. Use this interface in a manner similar to the Source Server.
If the Receive Pool already exists, the Receiver Server skips the step of creating the Receive Pool, and starts a new Update Process if one is not already running. Then it sets the restart flag in the Receive Pool that informs the Update Process to restart operations. The Receiver Server then continues operations in a manner similar to initial startup.
External control is required to start up and shut down Source and Receiver Servers. At shutdown, a Source Server in the active mode performs the following:
Flushes the dirty database cache buffers of all replicated regions
Transmits as many pending updates as possible to the Receiver Server within the specified time limit
Deletes the Journal Pool
Breaks the connection with the Receiver Server
Exits
An active Source Server becomes passive when deactivated. It flushes the database cache buffers of all the replicated regions and then "goes to sleep." At shutdown, a Source Server in passive mode flushes the database cache buffers of all the replicated regions and exits.
| |
Under normal operation, the Source Server should be shut down only after all M processes accessing the replicated regions have terminated. |
At shutdown, the Receiver Server sets a flag in the Receive Pool that signals the Update Process to shut down. When this flag is set, the Update Process flushes the database cache buffers of all replicated regions, sets a flag in the Receive Pool to inform the Receiver Server that the task is complete, and exits. Next, the Receiver Server confirms that the Update Process has exited, deletes the Receive Pool, breaks the connection with the Source Server, and exits.
An optional time-out parameter can specify the time to wait before signaling the Source or the Receiver Server to shutdown. An interface allows you to stop or start the Update Process independently of the Receiver Server. Refer to "Starting the Source Server." In case of a normal shutdown, the Update Process notifies the Receiver Server, which distinguishes this type of shutdown from a forced termination.
The Update Process reads journal records from the Receive Pool and applies the updates to the secondary database files. Under normal operation, with the exception of in-flight updates (i.e., those currently in the Journal Pool, Receive Pool, or the communication channel), the secondary database files reflect all database updates of the primary.
The Receiver Server starts the Update Process. The Update Process treats initial startup, and startup after recovery due to forced termination, in the same manner. At startup, the Update Process computes the reference point for starting operations (a JNL_SEQNO) in a manner similar to the Source Server's computation of the startup value of JNL_SEQNO. The Update Process writes this JNL_SEQNO into the Receive Pool. The Update Process then initiates a read of the Receive Pool for newly placed journal records. The Update Process reads and processes journal records as it receives them. The Update Process periodically checks to see if the restart flag is set in the Receive Pool. If the flag is set, the Update Process restarts operations from the startup stage.
GT.M's design allows the primary and secondary systems to operate on the same machine as separate instances.
Different instances of an application are distinguished by the value of the the logical name GTM$GBLDIR which defines a GT.M Global Directory. All processes of an instance must have the same value of GTM$GBLDIR.
A process accessing a database file in an instance must use the Global Directory of that instance. GT.M does not enforce this rule; however, violating this rule may lead to unpredictable results.
A set of commands implement filter activation and deactivation, and can be executed interactively or through a script.
Both Source and Receiver Servers can invoke filters. In the typical environment, the machine with the newer software will invoke filters. The filter should accept as input the logical database updates associated with a transaction and return the corresponding updates under the old or new schema, based on the purpose of the filter.
GT.M provides the following replication statistics:
The number of database transactions in the replication queue (i.e., the backlog of transactions not yet shipped to the secondary system)
The speed at which to send database transactions to the secondary system
When a primary system goes down and a secondary system takes over as the new primary. Un-replicated "in flight" transactions that do not appear in the new primary, may exist in the old primary. When the former primary comes up as the new secondary it will have transactions on its database that do not exist on the database of the new primary. To achieve database consistency, it must roll back the database to a synchronization point, or a transaction known to exist on the new primary. The transactions that are rolled off the former primary must be sent to the new primary for reconciliation.
To support rollback/recovery to a known synchronization point, the Source Server and the Update Process store records indicating the last point when the two systems were linked by replication, and the mode of each system (active or passive) at the time. This record provides the necessary information for a system that is starting as a secondary to find the synchronization point from the system that is operating as primary. When a system is in the primary role, it retains a record of the last database transaction sent to the secondary. When a system is in the secondary role, it retains a record of the last database transaction received from the primary. This information represents the last known point of synchronization.