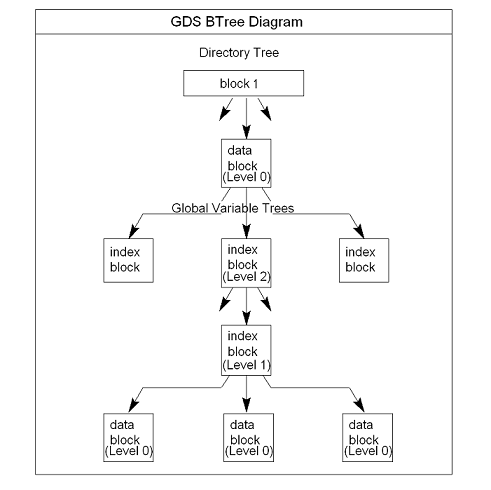
The GT.M database structure is hierarchical, based on a balanced tree (B-tree) structure. The B-tree contains blocks that are either index or data blocks. An index block contains pointers used to locate data in data blocks, while the data blocks actually store the data. Each block contains a header and records. Each record contains a key and data.
GDS structures the data into multiple balanced trees, or B-trees. A new B-tree, called a Global Variable Tree (GVT), is created each time a new global variable is defined. Each GVT stores the data for one global name (gvn). Global Variable Trees contain both index and data blocks and can span several levels. The data blocks contain actual global variable values, while the index blocks point to the next level of block.
At the root of the B-tree structure is a special Fidelity Information Services tree called a Directory Tree (DT). The Directory Tree contains pointers to the GVT. A data block in the Directory Tree contains an unsubscripted global variable name and a pointer to the root block of that global variable's GVT.
All GDS blocks in the trees have level numbers. Level zero (0) identifies the terminal nodes (i.e., data blocks). Levels greater than zero (0) identify non-terminal nodes (i.e., index blocks). The highest level of each tree identifies the root. All the B-trees have the same structure. Block one (1) of the database always holds the root block of the Directory Tree.
When a SET results in the first use of a global name by referring to a subscripted or unsubscripted global variable that has not previously appeared in the database, GT.M creates a new Global Variable Tree. GVT's continue to exist even after all nodes associated with their unsubscripted name are KILLed. Deletion of an empty tree requires a reorganization of the database file using MUPIP EXTRACT, CREATE, and LOAD.
The remainder of the chapter describes the details of the database structures.
Index and data blocks consist of a block header followed by a series of records.
The block header has three fields that contain information. The first field, of two bytes, specifies the number of bytes currently in use in the block. The second field, of one byte, specifies the block level. The last field of four bytes represents the transaction number at which the block was last changed.
Depending on the platform, there may also be an empty field containing filler to produce proper alignment. The filler occurs between the second and third data field and causes the length of the header to increase from seven to eight bytes. You can determine the size of the header by dumping the data block with DSE.
Records consist of a record header, a key, and either a block pointer or the actual value of a global variable name (gvn). Records are also referred to as nodes.
The record header has two fields that contain information. The first field, of two bytes, specifies the record size. The second field, of one byte, specifies the compression count.
Like the GDS block headers, a filler byte may be added, depending on the platform.
The compression count specifies the number of bytes at the beginning of a key that are common to the previous key in the same block. The first key in each block has a compression count of zero. In a global variable tree, only the first record in a block can legitimately have a compression count of zero.
Compression Count Example | ||
RECORD KEY | COMPRESSION COUNT | RESULTING KEY in Record |
CUS(Jones,Tom) | 0 | CUS(Jones,Tom) |
CUS(Jones,Vic) | 10 | Vic) |
CUS(Jones,Sally) | 10 | Sally) |
CUS(Smith,John) | 4 | Smith,John) |
The previous table shows keys in M representation. For descriptions of the internal representations, refer to the section on keys.
The non-compressed part of the record key immediately follows the record header. The data portion of the record follows the key and is separated from the key by two null (ASCII 0) bytes.
The data portion of a record in any index block consists of a four-byte block pointer. Level 0 data in the Directory Tree also consists of four-byte block pointers. Level 0 data in Global Variable Trees consists of the actual values for global variable names.
A key is an internal representation of a global variable name. A byte-by-byte comparison of two keys conforms to the collating sequence defined for global variable nodes. The default collating sequence is the one specified by the M standard. Refer to the "Internationalization" chapter in the GT.M Programmer's Guide for further details on defining collating sequences.
GT.M locates records by finding the last key in a block that is greater than or equal to (lexically) the current key. If the block has a level of zero (0), the location is either that of the record in question, or that of the (lexically) next record, if the record in question does not exist. If the block has a level greater than zero (0), the record contains a pointer to the next level to search.
GT.M does not require that the key in an index block correspond to an actual existing key at the next level.
The final record in each index block (the *-record) contains a *-key ("star-key"). The *-key is a zero-length key representing the last possible value of the M collating sequence.
The *-key is the smallest possible record, consisting only of a record header and a block pointer, with a key size of zero (0).
The *-key has the following characteristics:
A record size of seven (7) bytes
A record header size of three (3) bytes
A key size of zero (0) bytes
A block pointer size of four (4) bytes
Keys include a name portion and zero or more subscripts. Each subscript may be string or numeric and is formatted accordingly.
Keys in the Directory Tree represent unsubscripted global variable names. Unlike Global Variable Tree keys, Directory Tree keys never include subscripts.
Single null (ASCII 0) bytes separate the variable name and each of the subscripts. Two contiguous null bytes terminate keys. String subscripts and numeric subscripts are encoded differently.
During a block split the system may generate index keys which include subscripts that are numeric in form but do not correspond to legal numeric values. These keys serve in index processing because they fall in an appropriate place in the collating sequence. When DSE represents these "illegal" numbers, it may display many zero digits for the subscript.
The portion of the key corresponding to the name of the global variable holds an ASCII representation of the variable name excluding the caret symbol (^).
GT.M defines string subscripts as a variable length sequence of 8-bit ASCII codes ranging from 0 to 255.
To distinguish strings from numerics while preserving collation sequence, GT.M adds a byte containing hexadecimal FF to the front of all string subscripts. GT.M permits the use of the full range of ASCII characters in keys. Therefore, a null (ASCII 0) is an acceptable character in a string.
GT.M handles strings with embedded nulls by mapping 0x00 to 0x0101 and 0x01 to 0x0102. GT.M treats 0x01 as an escape code. This resolves confusion when null is used in a key, and at the same time, maintains proper collating sequence. The following rules apply to character representation:
All codes except 00 and 01 represent the corresponding ASCII value.
00 is a terminator.
01 is an indicator to translate the next code using the following:
Escape Code Translation in Keys
Code
Means
ASCII
01
00
<NUL>
02
01
<SOH>
Example:
Global Variable Name:
----
^NAME("A",$C(2,1,0),"B")
Internal Representation:
------------------------
4E 41 4D 45 00 FF 41 00 FF 02 01 02 01 01 00 FF 42 00 00
N A M E A $C(2) $C(1) $C(0) B
Numeric subscripts have the format:
[ sign bit ] [ biased exponent ] [ normalized mantissa ]
The sign bit and biased exponent together form the first byte of the numeric subscript. Bit seven (7) is the sign bit. Bits <6:0> comprise the exponent. The remaining bytes preceding the subscript terminator of one null (ASCII 0) byte represent the variable length mantissa. The following description shows how GT.M converts each numeric subscript type to its internal format:
Zero (0) subscript (special case)
Represents zero as a single byte with the hexadecimal value 80 and requires no other conversion.
Mantissa
Normalizes by adjusting the exponent.
Creates packed-decimal representation.
If number has an odd number of digits, appends zero (0) to mantissa.
Adds one (1) to each byte in mantissa.
Exponent
Stores exponent in first byte of subscript.
Biases exponent by adding hexadecimal 3F.
The resulting exponent falls in the hexadecimal range 3F to 7D if positive, and zero (0) to 3E if negative.
Sign
Sets exponent sign bit <7> in preparation for sign handling.
If mantissa is negative: converts each byte of the subscript (including the exponent) to its one's-complement and appends a byte containing hexadecimal FF to the mantissa.
Example:
Global Variable Name:
----
^NAME(.12,0,"STR",-34.56)
Internal Representation:
------------------------
4E 41 4D 45 0 BE 13 0 80 0 FF 53 54 52 0 3F CA A8 FF 00 00
N A M E .12 0 S T R -34.56